Lukas Fluri
Open Menu
Close Menu
Bio
News
Papers
Blog
Reinforcement Learning
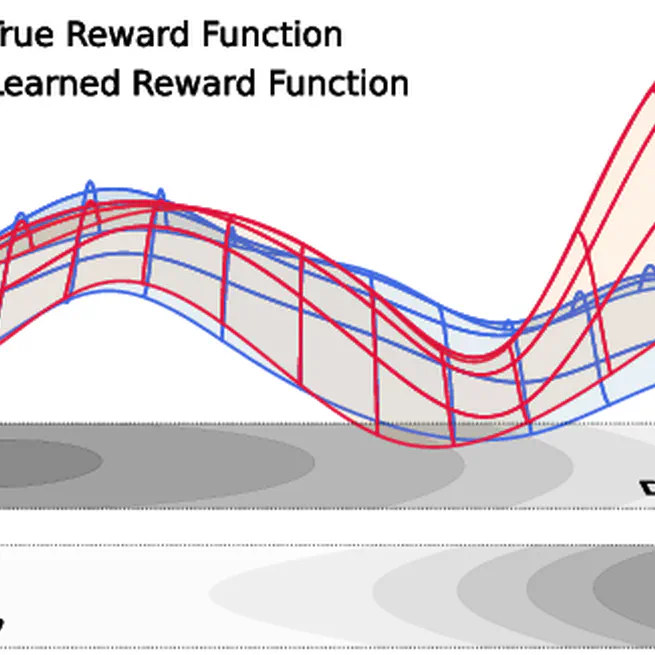
The Perils of Optimizing Learned Reward Functions: Low Training Error Does Not Guarantee Low Regret
May 1, 2025